
从Project Loom诞生以来,社区都非常关注Java中协程的实现,终于在JDK 19中以预览API的形式开放使用。JDK 21 的 Features 已经正式包含了 JEP 444: Virtual Threads ,这意味着在下一个LTS版本(JDK 23)虚拟线程将正式投入大规模使用。
虚拟线程引入JDK
在JDK 19的Features中加入了Virtual Threads (Preview),这意味着一个完全开发完成的Java版的协程已经处于可用阶段了,并且在不久的将来Java虚拟线程会去掉预览,成为Java语言的正式功能。JDK 21 的 Features 已经正式包含了 JEP 444: Virtual Threads ,这意味着在下一个LTS版本(JDK 23)虚拟线程将正式投入大规模使用。
JDK引入协程的动力
在讨论Java为什么引入协程之前,我们必须先讨论Java原有的线程模型,这是Java在服务端成功的重要原因。我们再来讨论Java原来的线程模型的局限性,以及其迫切升级的原因。
线程模型
线程(Thread)是操作系统中一个重要概念,是独立调度和分派的基本单位。线程的执行由线程的调度方决定,而调度可以在内核级或者用户级执行,多任务调度也可以是抢占式或协作式。我们先来简单介绍一些术语。
术语
进程: 进程是操作系统中执行中的程序实体,是系统进行资源分配的基本单位,一个进程由一个或者多个线程组成。进程由操作系统内核直接创建调度。进程中的线程是基本的调度和执行单位,根据方式不同,分为内核线程或用户线程。
内核线程: 内核线程是内核的基本调度单元,这种线程由内核直接调度,每个进程中至少存在一个内核线程,在一个进程中存在多个线程的情况下,内核线程的调用根据操作系统的调度模式执行(一般是抢占式调度)。内核线程仅由堆栈、寄存器的副本和线程本地存储(Thread-local storage),其他资源都是进程中共享的,所以其创建和销毁产生的开销远低于进程。内核线程的切换开销相对较低,只需要保存恢复寄存器和堆栈指针。但是内核线程需要消耗内核资源,一个系统中的内核线程是有限的。程序一般不会直接创建内核线程,而是通过内核线程的高级接口——轻量级线程(Light-weight process,LWP)创建。
用户线程: 在用户空间中实现的的线程叫做用户线程。用户线程完全在在用户空间进行调度和管理,换句话说用户自己管理的线程叫做用户线程,所以内核并不知道用户线程,在用户线程切换时,完全不需要与内核交互,所以其上下文切换非常高效。完全不需要内核的参与也带来和坏处,用户必须完整的实现用户线程的调度,而且一旦发生阻塞将导致其他用户线程无限等待,要解决起来十分困难。
线程模型-内核级线程
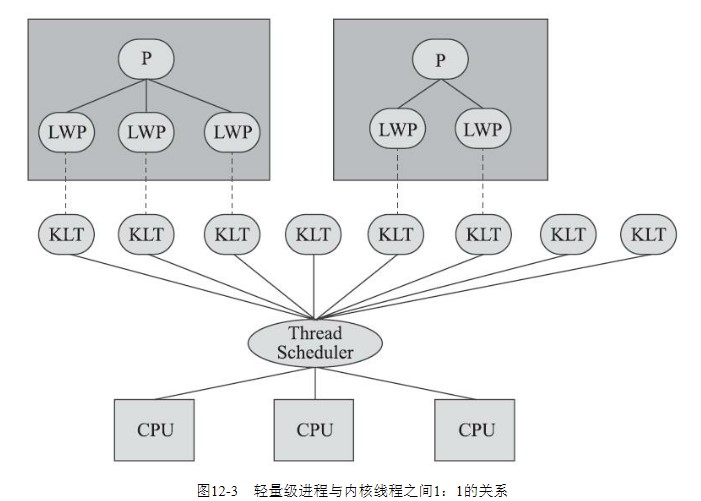
内核线程:用户线程 = 1:1
内核线程与用户线程以1:1的比例创建,这种方式实现简单,而且由内核来完成线程的切换和调度。当前Java就是内核级线程的实现。
线程模型-用户级线程
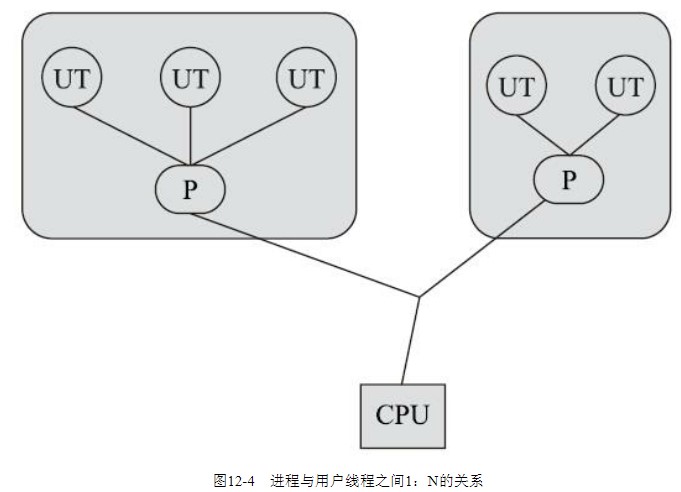
内核线程:用户线程 = 1:N
用户级线程实现是指由一个内核线程实现多个用户线程,这种方式上下文切换非常高效,但是实现难度太高,Java远古时代(1.2以前)就是利用这种方式实现的线程(Green Threads),但是当绿色线程执行阻塞系统调用时,不仅该线程被阻塞,而且进程中的所有线程都被阻塞,所以绿色线程必须使用异步 I/O 操作。
线程模型-混合线程
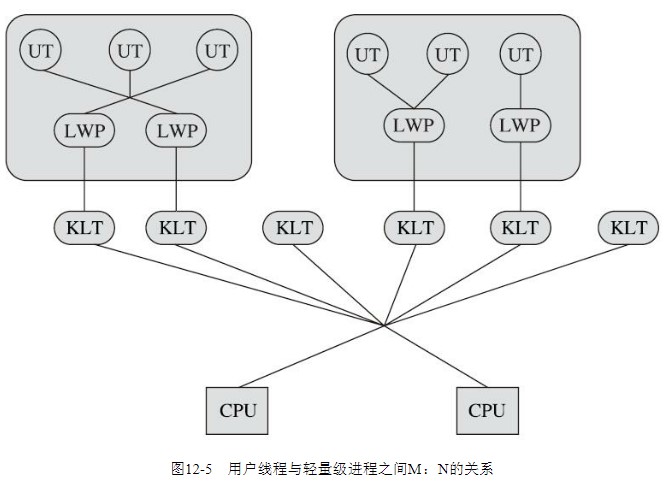
内核线程:用户线程 = M:N
Java线程模型以及现有问题
Java线程本质上是内核级线程(内核线程:用户线程 = 1:1),由内核线程直接实现。这样做的好处是将线程的调度交给内核处理,简化了线程的实现难度,并且现代操作系统一般不会因为一个线程阻塞而导致整个程序阻塞。但是在云技术发展的今天,暴露了内核线程无法解决的问题。
问题一:内核线程上限
上文中提过,内核线程由内核创建,每个内核线程都要消耗一些资源,而内核的资源是有限的,所以OS肯定不会任由程序无限的创建下去。在Linux中/proc/sys/kernel/threads-max是内核线程总数量。
1 | cat /proc/sys/kernel/threads-max |
ubuntu 22.04 上的内核线程默认限制为125375。
1 | echo 100000 > /proc/sys/kernel/threads-max |
虽然默认125375看起来很多,但是这是整个操作系统的内核线程限制,一个进程很难能够申请所有的线程,而且一个Java进程在运行几千进程的时候就很难保证系统稳定性了。我曾在Windows下运行canal的某个有BUG的测试版本,这个BUG会导致canal一直创建线程,在观察到canal创建超过3000个线程的时候,进程变得摇摇欲坠随时退出。
一般程序数百个线程就够用了,Java runtime同时处理几百个线程的能力不在话下,其简单而又强大的API是Java近30年来昌盛的原因。在服务应用方面,为保持简单性,Java一直采用thread-per-request风格(每个请求一个线程)来处理用户请求,所以在客户端发起请求的整个持续时间内,服务器需要分出一个线程去处理请求的整个生命周期。这种风格让程序变得易于理解、开发和调试。就像JEP 425中说的:
it uses the platform’s unit of concurrency to represent the application’s unit of concurrency.
它使用平台的并发单位来表示应用程序的并发单位。
——JEP 425
既然内核线程被内核资源限制,而又需要少创建线程,那么就尽量重复使用线程是否可行?答案是可行,而且近30年来Java程序员都是这么干的,这种做法被叫做池化,但是程序员一般是站在线程创建和销毁开销的角度来创建线程池的,在云服务发展的今天服务器或许能同时处理超过上百万的并发套接字,但是线程池不可能同时维护上百万个线程,同时维护这些线程不仅是对资源极大的浪费,而且这对Java平台来说几乎不可能实现。
根据Little定律,对于指定延迟,吞吐量增长必须要求服务应用的并发成比例的增长才能满足要求。例如一个平均延迟100ms的系统需要10个并发处理单元来实现每秒100次请求的吞吐量;而每秒1000次请求的吞吐量在100ms的延迟下需要100个并发处理单元才能满足要求。要提升应用吞吐量必须提升应用并发能力,内核线程又限制线程并发数量,在实际情况中CPU和网络资源耗尽之前,往往是线程资源先耗尽,导致应用的吞吐量远低于实际硬件所支持水平。
在一个稳定的系统中,长期的平均顾客人数(L)=长期的有效抵达率(λ)* 顾客在这个系统中平均的等待时间(W):
——Little定律
如果放弃thread-per-request风格,采用异步的方式实现并发,是否可以摆脱这个限制?
问题二:复杂的异步风格
有些程序员希望最大程度的利用硬件的性能,考虑到thread-per-request将浪费内核资源,于是考虑直接使用异步API实现thread-sharing风格。在thread-sharing风格下,不再是一个线程从请求开始执行的请求结束的最后一行代码,而是在等待I/O或者其他长时间的操作时将线程还给调度者,调度者将此线程去执行其他服务。这样仅仅在执行时才会代码占用线程,I/O的时间越长理论上支持的请求数量越多,而且并不会消耗大量线程,人为的绕过了内核对于线程的限制。代价就是:异步编程风格。相信感受过异步编程的程序员都对它的调试部分印象时刻,在复杂的逻辑里大量使用异步编程将会使得代码的可读性变得很差,在Java中你或许需要CompletableFuture来实现异步操作,满屏的lambda表达式和回调函数将是阅读代码的强力阻碍,JDK的堆栈跟踪所提供的上下文或许也基本没有意义了。也就是说在当前的Java平台为了应用的并发,将以代码的可读性和可调试性为代价,在大型应用上这是得不偿失的。
1 | fs.readdir(source, function (err, files) { |
Java如何提升并发?
Project Loom的目标
在Loom的早期阶段,由Loom的Owner——Alan Bateman写的文章《Project Loom: Fibers and Continuations for Java》中曾表示,他们将为Java平台添加一个轻量级线程—fiber(纤程),但是后来明显没有再用这个名字了。在次年Alan Bateman又写了了一篇文章《A lightweight thread is a Thread》,在这篇文章中Alan Bateman表示轻量级线程还是改用Thread表示,代表轻量级线程的术语也由Fiber变成了lightweight thread。
从Loom早期阶段来看,JDK开发人员对提升Java并发的手段就是通过用户线程实现,golang和Erlang已经证明这是一条很有效的路径,他们初步打算重新引入一个概念Fiber实现他们的构想。
在中期,Loom将Fiber完全改为Virtual Thread,fiber这个词至少在JDK19中我用全局搜索也没找到。
计算续体(Continuations)的实现
在《Project Loom: Fibers and Continuations for Java》一文中官方就提到了计算续体,计算续体实际是一种保留上下文的抽象,它表达了程序在运行过程中某一点的计算状态,这里文章中用注释指出计算续体也叫做协程,但是只是一个临时名字,在后期的文章中没有在出现了。
协程(coroutine)和纤程(fiber)的区别:协程比较形象,就是代码之间相互协作,每个协程确保在等待的时候主动让出计算资源,也就是由用户代码完全管理计算资源;而纤程则是有一个专门调度器(Scheduler)来协调计算资源。
所以Java的用户级线程在开始的时候会被叫做纤程的原因就是Java的用户级线程是存在调度器的。
我们先来看下计算续体Loom对计算续体的要求:
- 计算续体能够挂起和恢复运行,它能够保持自己执行的位置。
- 计算续体应该是有栈协程,才能在何栈嵌套深度中阻塞。而非无栈协程是能在相同入口点处暂停与执行。
- 计算续体应该是有状态的,运行过的位置不能再次运行,其是不可重入的。
示例来自Project Loom: Fibers and Continuations for Java
1 |
|
创建了一个计算续体 (0),其入口点为foo()然后调用它 (1),将控制传递给计算续体 (2) 的入口点,然后继续执行直到 bar 子例程内的下一个挂起点 (3),此时调用 (1) 返回。当再次调用继续 (4) 时,控制返回到暂停点 (5) 之后的行。
虚拟线程(Virtual Threads)的实现
在经历Fiber和lightweight Thread后Loom最终把JDK命名为Virtual Thread,并且将虚拟线程融入了Java生态环境。现在Java中Thread有两个含义(实现):一种叫做平台线程(Platform Thread)指内核级线程、而另一种叫做虚拟线程指用户级线程。
为了使JDK兼容虚拟线程,Loom做的努力
java.lang.Thread
新的API:
Thread.ofVirtual()为创建虚拟线程的方式Thread.ofPlatform()为创建平台线程的方式Thread.startVirtualThread()创建虚拟线程并且运行的方式Thread.isVirtual()检测当前线程是否为虚拟线程Thread.getId()启用,新API为Thread.threadId()Thread.getAllStackTraces()返回所有平台线程的映射
平台线程和虚拟线程在不同API上的表现:
new Thread()无法创建虚拟线程Thread.setDaemon(boolean)虚拟线程总是守护线程,此方法在虚拟线程上无效Thread.setPriority(int)虚拟线程的优先级固定为Thread.NORM_PRIORITY.,此方法在虚拟线程上无效。(但是未来可能会考虑虚拟线程的优先级)Thread.getThreadGroup()虚拟线程没有线程组,此方法返回的是‘VirtualThreads’的字符串,没有特别的意义- 使用 SecurityManager 集运行时,虚拟线程没有权限。
- 虚拟线程不支持
stop()、suspend()或resume()方法。这些方法在虚拟线程上调用时会抛出异常。
Thread-local variables
- 虚拟线程可以使用
ThreadLocal和InheritableThreadLocal - 但是虚拟线程非常多,需要仔细考虑是否有必要使用
allowSetThreadLocals可以禁止虚拟线程设置ThreadLocal,在大量虚拟线程的情况下很有效- 在一些情况下,范围变量(Scope-local variables)能很好的替代
ThreadLocal
java.util.concurrent
java.util.concurrent.LockSupport对虚拟线程支持Executors.newThreadPerTaskExecutor(ThreadFactory)和Executors.newVirtualThreadPerTaskExecutor()可以为每一个任务创建一个新(虚拟)线程ExecutorService支持了AutoCloseable
Networking
java.net.Socket,ServerSocket,DatagramSocket可以在虚拟线程中使用,并且其在虚拟线程中使用时可以中断,其中断后将关闭套接字并取消挂起线程
java.io
BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter、PrintStream和PrintWriter现在在直接使用时使用显式锁而不是监视器锁。InputStreamReader和OutputStreamWriter使用的流解码器和编码器现在使用与封闭的InputStreamReader或OutputStreamWriter相同的锁。- 此外,
BufferedOutputStream、BufferedWriter和OutputStreamWriter的流编码器使用的缓冲区的初始更小,以便在堆中有许多流或编写器时减少内存使用。例如有一百万个虚拟线程,可能会出现每个都在套接字连接上有一个缓冲流。
Java Native Interface (JNI)
- JNI 定义了一个新函数
isVirtualThread,用于测试对象是否为虚拟线程。
Debugging (JVM TI, JDWP, and JDI)
- Java 调试有线协议 (JDWP) 和 Java 调试接口 (JDI)。所有三个接口现在都支持虚拟线程。
JDK Flight Recorder (JFR)
JFR 通过几个新事件支持虚拟线程:
jdk.VirtualThreadStart和jdk.VirtualThreadEnd表示虚拟线程的开始和结束。默认情况下禁用这些事件。jdk.VirtualThreadPinned指示虚拟线程在固定时停放,即没有释放其平台线程(参见讨论)。默认情况下启用此事件,阈值为20ms。jdk.VirtualThreadSubmitFailed表示启动或取消虚拟线程失败,可能是由于资源问题。默认情况下启用此事件。
Java Management Extensions (JMX)
java.lang.management.ThreadMXBean只支持平台线程的监控和管理。findDeadlockedThreads()方法查找处于死锁状态的平台线程的循环;它没有找到处于死锁状态的虚拟线程循环。com.sun.management.HotSpotDiagnosticsMXBean中的新方法生成上述新型线程转储。也可以通过平台MBeanServer从本地或远程JMX工具间接调用此方法。
java.lang.ThreadGroup

虚拟线程的使用
在JDK 19中试用
虚拟线程在JDK 19中作为预览API需要添加--enable-preview参数,才能正常编译
环境
OS:Windows 11专业版64位(10.0,版本22623)
JDK: openjdk version “19.0.1” 2022-10-18
CPU:AMD Ryzen 7 4800H with Radeon Graphics
RAM: 32768MB
接口使用
1 | Thread.ofVirtual().start(() -> System.out.println("Virtual")); |
1 | try (var executor = Executors.newVirtualThreadPerTaskExecutor()) { |
虚拟线程的创建销毁开销很低,池化没有意义,Executors.newVirtualThreadPerTaskExecutor()也是每次创建的新虚拟线程
性能测试
1 | public class Main { |
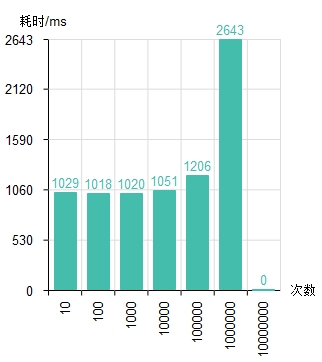
- 在执行次数10000及以下时执行时间仅有的1s,令人震惊。
- 在1000000的时候执行时间翻倍,这或许和虚拟线程的调度机制有关,目前暂时不了解。
- 在10000000时,我运行了15个小时也没出结果,而且CPU一直是满负荷状态。这可能是JDK的一个BUG。
时间线
JDK 21 的 Features 已经正式包含了 JEP 444: Virtual Threads ,这意味着在下一个LTS版本(JDK 23)虚拟线程将正式投入大规模使用
Java虚拟线程的正式发布
JDK 20 的 Features 已经包含了 JEP 436: Virtual Threads (Second Preview)
Java虚拟线程的二阶段预览
令人激动的消息,Java继绿色线程(Green Thread)退出Java平台后重新迎来的一个新的用户模式线程,现在虚拟线程带着Java平台的高并发期望回来。
将虚拟线程以预览API的形式引入Java平台。
为主机名和地址解析定义服务提供者接口 (SPI),以便 java.net.InetAddress 可以使用平台内置解析器以外的解析器。平台内置解析器会阻塞至系统返回结果。Project Loom现在可以利用SPI直接实现 DNS 客户端协议,而不会阻塞。
讨论虚拟线程在网络I/O的应用
给出的virtual thread的定义。
抛弃Fiber(纤程),将轻量级线程的名字正式命名为Virtual Thread(虚拟线程)
在本篇文章中Project Loom的Owner——Alan Bateman讨论了轻量级线程(Lightweight Thread)、纤程(Fiber)、线程(Thread)的关系,他认为轻量级线程应该用线程来表示。
Loom的第一个二进制版本。
Project Loom的目的:使编写、调试、分析和维护并发应用程序变得更加容易。